
What's long-term about "longtermism"?
Trying to curb existential risk seems important even without big philosophy ideas

I never know how much to worry about the names of things.
It’s pretty clear, for example, that the conservative movement in the United States is not just the name of people who really like the status quo.1 When the Supreme Court overturned Roe v. Wade, conservatives were thrilled and nobody found that confusing. There are certainly aspects of the status quo that conservatives seek to conserve, but they also favor plenty of large policy changes. And that’s not a paradox or a contradiction — words and names just carry a certain amount of ambiguity.
But I do think this causes confusion when we talk about relatively new and potentially fast-changing ideas.
The Effective Altruism movement was born out of an effort to persuade people to be more charitable and to think more critically about the cost-effectiveness of different giving opportunities. Effective Altruism is a good name for those ideas. But movements are constellations of people and institutions, not abstract ideas — and over time, the people and institutions operating under the banner of Effective Altruism started getting involved in other things.
My sense is that the relevant people have generally come around to the view that this is confusing and use the acronym “EA,” like how AT&T no longer stands for “American Telephone and Telegraph.”
But after reading Will MacAskill’s book “What We Owe The Future” and the surge of media coverage it generated, I think I’ve talked myself into my own corner of semi-confusion over the use of the name “longtermist” to describe concerns related to advances in artificial intelligence. Because at the end of the day, the people who work in this field and who call themselves “longtermists” don’t seem to be motivated by any particularly unusual ideas about the long term. And it’s actually quite confusing to portray (as I have previously) their main message in terms of philosophical claims about time horizons. The claim they’re making is that there is a significant chance that current AI research programs will lead to human extinction within the next 20 to 40 years. That’s a very controversial claim to make. But appending “and we should try really hard to stop that” doesn’t make the claim more controversial.
In other words, there’s nothing philosophically controversial about the idea that averting likely near-term human extinction ought to be a high priority — the issue is a contentious empirical claim.
This is a very genuine change
I think the confusion here stems not only from the terminology but from the history of the movement.
Since the days of spell-it-out Effective Altruism, there has always been plenty of controversy over questions like “exactly how cost-effective is it to give out bed nets to combat malaria versus giving direct cash transfers to low-income people in poor countries?” But there have also always been tons of people giving money to causes that are obviously less cost-effective on a per-life-saved basis than either of those. I went to the National Aquarium in Baltimore recently and there’s a whole wall listing the names of people who chose to give money to advance the cause of putting fish on display for public edification. I know people who choose to work hours providing pro bono legal counsel to poor people accused of crimes in the United States when they could spend that time billing rich people accused of crimes at a high rate and donating the money.
I don’t think the fish donors or pro bono death penalty attorneys are confused about the cost-benefit — they have decided, based on either their considered ethical view or a lack of adequate reflection, that maximizing the number of lives saved is not the most important thing.
The term “Effective Altruism,” spelled out as words, carried the meaning that you — a middle-class resident of a developed country — should be less parochial and try to identify objectively urgent and underfunded causes.
And this was primarily a challenge on the level of values. Ideas like “Burundi is poorer than Baltimore” or “public health programs save more lives than aquariums” or “lots of rich people are already doing locally-focused philanthropy” are not empirically contentious or interesting to argue about. The empirical disputes about malaria versus worms versus cash transfers are an internal dialogue among people who are bought in on the merits of trying to address the material needs of the poorest.
But if, while investigating some aspect of a bed net program, you unearthed a new malaria parasite whose biological properties made it very likely to lead to human extinction within the lifespan of people currently alive today, the important thing would be to persuade people that this is factually true, not to persuade people of the broad worldview that led you to investigate the parasite in the first place.
Who cares about the long term?
The best way to explain longtermism as an idea rather than as a movement is with some weird math.
Derek Parfit says in “Reasons and Persons” says that most people probably think of “nuclear war kills 99.9 percent of humanity” and “nuclear war kills 100 percent of humanity” as pretty similar outcomes. But he thinks that’s wrong. A war that kills 99.9 percent of humanity still leaves 70 million people, which is actually a larger population than has existed for the vast majority of Homo sapiens’ 300,000-year run.

Those 70 million survivors could easily persist for another couple of thousand years, have a new Industrial Revolution, experience a new population boom, and someday colonize the whole galaxy. Over the course of the next 10,000 years, the difference between a nuclear exchange that kills 99.9% of the population and an exchange that kills everyone could amount to hundreds of billions of people.
If you take these ideas seriously, some of the thought experiments you come up with in philosophy class can lead to some pretty odd conclusions. Suppose right now there’s a 0.001 percent chance that climate change could generate a catastrophic feedback mechanism that leads to human extinction, and doing a Thanos snap and killing half of everyone reduces that to 0.0001 percent. A certain kind of longtermist logic says you should do the snap, which I think most people would find odd.
But even though I was a philosophy major in college and find this interesting to argue about, it’s actually not the sort of thing the people in EA who self-identify as longtermists are worried about when it comes to AI.
The AI Worriers are worried about large, short-term risks
Ajeya Cotra wrote a report two years ago focused on trying to predict the future pace of artificial intelligence progress based on what we know about human biology.
She came away with the idea that transformative AI was likely to arrive around the year 2050, which was exactly 30 years in the future at the time she published the report. There’s a joke that AI researchers always believe super-powerful AI is 30 years away, so a lot of folks may have dismissed her conclusions. But in light of recent real-world progress, her median date is now 2040, only 18 years in the future.
Cotra also believes that, in the absence of specific countermeasures (which have not thus far been taken), the AI research programs currently underway at many American technology companies are “likely to eventually lead to a full-blown AI takeover (i.e. a possibly violent uprising or coup by AI systems).”
Set aside for a moment whether you think these predictions are outlandish. I think the salient thing about this claim — “malevolent AIs will probably take over the world before your new roof needs to be replaced” — is that if it’s true, it’s obviously very important regardless of your value system. Whether you are someone who cares a lot about the fate of his local community, someone who cares a lot about fish, someone who cares a lot about arts and culture, or even just a very self-centered person who only cares about herself and her family, this looming high probability of human extinction is a big deal.
It’s not super obvious that the basic tenets of Effective Altruism movement would lead to concern about runaway AI,2 even though ideas like “people should be more altruistic and more focused on cost-effectiveness” and “people should be more focused on the long term” are very relevant to that story.
But the outcome of growing EA interest in longtermism wasn’t just “and then they identified a low-probability source of long-term risk and had to try really hard to persuade people to take low probabilities of long-term risk seriously.” The outcome was “they identified what they believe is a high probability short-term risk.” The claim is that we are like Sarah Connor in the 1990s, with multiple different profit-seeking companies trying to build systems that will probably kill us. That conclusion might be wrong, but if you were convinced that it was true, I don’t think it would be very difficult to persuade you of the additional point that it’s worth caring about.
What is the upshot of any of this?
Eli Lifland read a bunch of arguments along these lines and “decided to stress test it,” and he claims that you actually do need to consider future people in order to reach the conclusion that prioritizing existential risk makes sense.
You can read the entire post if you want, but my basic objection is that the whole idea of prioritizing here is a little bit fake.
The typical person’s marginal return on investment for efforts to reduce existential risk from misaligned artificial intelligence is going to diminish at an incredibly rapid pace. I have written several times that I think this problem is worth taking seriously and that the people working on it should not be dismissed as cranks. I’m a somewhat influential journalist, and my saying this has, I think, some value to the relevant people. But I write five columns a week and they are mostly not about this, because being tedious and repetitive on this point wouldn’t help anyone. I also try to make it clear to people who are closer to the object-level work that I’m interested in writing columns on AI policy if they have ideas for me, but they mostly don’t.
So am I “prioritizing” AGI risk as a cause? On one level, I think I am, in the sense that I do literally almost everything in my power to help address it. On another level, I clearly am not prioritizing this because I am barely doing anything.
On global public health, by contrast, we can (and do!) give 10 percent of our subscription revenue to the GiveWell Maximum Impact Fund, and I regularly tout said fund to others and suggest people contribute to it. Is that prioritizing? Well, it’s a meaningful share of our income. But we’re not experiencing any material deprivation, and it’s not time-consuming or logistically burdensome to help save people’s lives through this kind of giving.
Where I’m going with this is that while I’ve often urged more emphasis on priority-setting, I think the quest for the One True Top Priority involves positive tradeoffs that aren’t necessarily real.

For example, in my portfolio of “columns related to topics that EAs consider to be major existential risk priorities,” I have written more about pandemic prevention than artificial intelligence. That’s not because I particularly dispute the probability weighting, it’s because I actually have specific things to say and advocate for on the pandemic front. The big challenge I face is that I need to write a lot of columns and make them interesting and engaging and informative. I face plenty of tradeoffs in life, but not the particular kind of tradeoff suggested by the prioritization debate.
Doing more good
Tyler Maule recently posted this helpful chart of EA funding by cause area, which shows that, in practice, the influx of money for catastrophic risk and EA infrastructure-building has been additive rather than crowding out global health and development funding. So people who worry that the pondering of outlandish-sounding scenarios is coming at the expense of alleviating immediate suffering should find some solace in that.
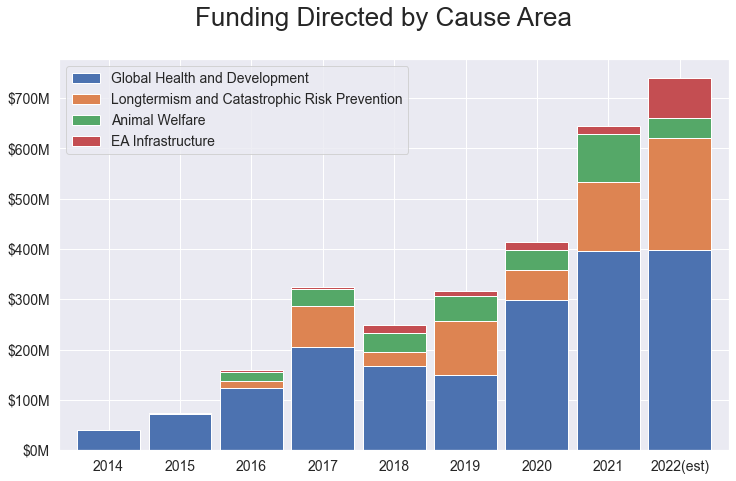
Now another question you could ask is whether we’re missing out on an opportunity to avert human extinction because some people are wasting hundreds of millions of dollars on preventing kids from dying of malaria. That would be an interesting claim. But in my reading of participants in prioritization debates, I’ve never actually seen someone say they’re $75 million away from executing an extinction-averting plan that has a high probability of success. What’s more, if someone did come up with a plan like that, I’m pretty sure they could get the money.
I think the real takeaway from this chart is that even with the recent influx of Sam Bankman-Fried money, the total funding in this space is relatively small.
Huge sums of money are moved philanthropically on the basis of what is clearly sentimentality or egomania without even a hint of a suggestion of a serious effort to be of service to the world. Stephen Schwarzman gave $150 million to renovate a Yale building and establish a “center dedicated to cultural programming and student life at the center of the university.” It’s not clear to me that makes the world a better place at all, much less that it counts as cost-effective philanthropy. But Schwarzman went to Yale, and he seems to be really into Yale. Joanne Knight gave $15 million to Cornell to establish a business school deanship named in honor of her late husband, who had three Cornell degrees.
I say this not particularly to pick on those two but just to remind people that the uncontroversial-among-smart-writers part of EA — that you should try to give money to stuff that is worthwhile rather than try to get stuff at the richest universities in the world named after your family — is extremely controversial relative to the observed behavior that we see in the real world. And the observation that people who are much less rich than the Schwarzmans and the Knights of the world are still affluent enough to be able to save lives by increasing our charitable giving is also controversial.
It’s paradoxical and I think fundamentally bad that people who are making a good-faith effort to use their money for human betterment end up attracting more criticism and scrutiny than the people who are spending it on things with obviously low value. But Schwarzman is a smart guy. If he set about to give $150 million to the very best cause in the world, I might not end up agreeing with his judgment, but I’m sure he himself wouldn’t land on “build a fancy cultural center for Yale students.” It’s just that he’s operating in a universe where a rich person can pick up more social esteem by writing checks to his alma mater than he can by making any sort of good-faith effort to identify the best use of his money.
And that is a much bigger problem for the world than the exact resolution of internecine optimization battles. If we can get everyone to be a bit more charitable and to at least try to identify some kind of plausible candidate for “this is really important and underfunded,” there’s a lot that can be accomplished.
People sometimes talk about small-c conservative politics to distinguish it from conservative movement politics, but even that doesn’t make much literal sense since this isn’t the UK and we don’t have a capital-c Conservative Party.
There’s an interesting historical story about how Holden Karnofsky and Ellie Hassenfeld wanted to found an organization dedicated to helping people identify cost-effective charities. They got connected with Dustin Moskovitz who had a lot of money courtesy of Facebook, and he funded their work but also expanded to start looking at bigger-picture causes. That came to expand to consider genuine existential risk (rather than just “lots of people die”) as an important, distinct field of study. And that’s how someone came to be paying Ajeya Cotra to do this work on AI risk.
I already find these AI risk columns tedious and repetitive. Matt might as well have written multiple essays on how the Reasonabilists have new convincing arguments about how imminently Zorp the Surveyor is coming to destroy the world.
"[The fish donors and pro bono death penalty attorneys] have decided, based on either their considered ethical view or a lack of adequate reflection, that maximizing the number of lives saved is not the most important thing."
I think this claim gives too little credit to the donors and attorneys, who probably wouldn't disagree that maximizing the number of lives saved is the most important thing. I think their reasoning – or, at least, my reasoning if I were in their shoes – would be that maximizing the number of lives saved isn't *their particular part to play in the betterment of society*. There is clearly no shortage of vital work to be done; I've figured climate change is a major threat to human well-being and have decided to try to make a career of fighting it, using what I think are my most valuable skills (research, communication, math, generally holding a lot of facts in my head). This isn't to disparage other priorities – it just seems like this is where I can help (it turns out employers disagree, though, so who knows).
One of the things I find most grating about social-justice leftism is its transcendental-meditation-esque belief that we can and should have a planned attention economy, wherein everyone focusing their attention at the same time on e.g. Covid-19 or racial justice is necessary and sufficient to fix those problems. It would be a bummer if EA turned into just a mathed-up version of that. Not only are we never going to achieve worldwide consensus ordered prioritization of all good works that need to be done, there's a point of diminishing returns where by turning everyone's focus towards one thing we lose the gains from specialization. This isn't a criticism of EA as a philosophy, which is a valuable corrective to the norm of locally focused giving, as Matt points out. But it is a warning against the risk that the EA movement trips over its own feet in the future by not telling individuals to factor the existing landscape of philanthropy into their calculations.